4月1日,谷歌针对其压缩算法TurboQuant论文引发的争议作出了回应。尽管团队试图通过“技术澄清”平息争议,但关于核心技术相似性的指控仍未得到解决。谷歌辩称随机旋转是标准技术,并认为实验基准中的错误对事实影响不大。

3月底,谷歌官方博客高调宣传了这篇论文,声称TurboQuant能将大语言模型的KV缓存内存占用减少至少6倍,速度提升高达8倍,且精度零损失。这一消息导致全球存储芯片股大跌,美光、SK海力士和三星电子等公司市值蒸发超过900亿美元。华尔街担心,如果软件能大幅压缩AI内存需求,芯片硬件的增长逻辑可能需要重写。
然而,反转很快到来。3月27日,RaBitQ作者、苏黎世联邦理工学院博士后高健扬在知乎发布长文,指控谷歌团队存在学术不端行为。舆论迅速转向对谷歌学术诚信的质疑。业界普遍认为,RaBitQ率先提出了原创方法,而TurboQuant在其基础上进行了优化,却未给予应有的引用与尊重,甚至对其进行了不公正的贬低。
4月1日,论文第二作者Majid Daliri代表团队在OpenReview平台上发布了四点“技术澄清”。谷歌辩称,TurboQuant的核心方法并非源自RaBitQ,因为随机旋转是一种标准技术,在RaBitQ之前已被广泛使用。TurboQuant的真正创新在于推导出了旋转后的坐标分布。不过,学术圈认为,即使某项技术是行业常识,首次将其应用于特定领域的人也应得到应有的认可。
关于贬低RaBitQ理论为“次优”的指控,论文作者承认由于没有仔细阅读对方附录,漏了一个常数因子,导致得出了草率结论。现在他们发现RaBitQ确实是最优的,正在更新TurboQuant手稿。然而,一篇顶会论文对同行核心理论的负面评价建立在“没看清附录”的基础上,这一解释难以令人信服。
对于“把对手绑住手脚再赛跑”的指控,Majid Daliri表示,即使省略与RaBitQt的运行时比较,该论文的科学影响和有效性也基本保持不变。因为TurboQuant的主要贡献在于压缩质量的权衡,而不是特定的加速。此前高健扬披露,谷歌团队测试RaBitQ时使用单核CPU并关闭多线程,测试TurboQuant时则采用英伟达A100 GPU。尽管团队宣称速度对比并非核心,论文中仍将速度作为关键卖点之一。
谷歌在回应中暗示对方“别有用心”,指出论文自2025年4月就在arXiv发布,对方有将近一年时间通过学术渠道提问题,却等到论文获得广泛关注后才闹大。高健扬回应称,早在2025年5月双方就通过邮件私下沟通,同年11月还曾联系ICLR组委会,但均未得到有效回应。直到谷歌通过官方渠道将论文推上千万级曝光量的神坛,学术纠正才变得迫在眉睫。
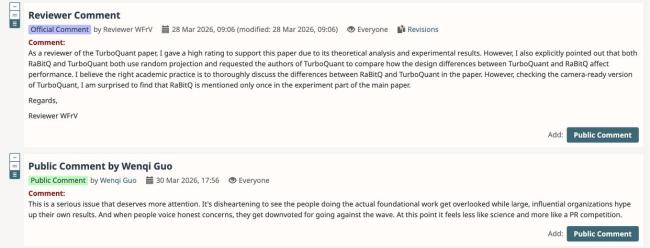
在OpenReview上,有研究者评论这是一个值得更多关注的严重问题,感觉不像是科学,更像是一场与大厂的公关竞赛。同时,TurboQuant论文的审稿人也站出来表达态度,称由于其理论分析和实验结果,对这篇论文曾给予了很高的评价。但审稿时惊讶地发现RaBitQ在主论文的实验部分只提到过一次。
不可否认,TurboQuant在技术层面具备商业潜力。一位人工智能硕士在知乎上分析称,在大模型推理场景中,KV缓存内存占用直接决定单卡可同时处理的请求数量,是推理服务商最核心的经济指标。同样一张卡,并发量若提升6倍,每个请求的推理成本理论上可降至原来的六分之一。对于那些每天处理数十亿次API调用的AI厂商而言,这将是一项巨大的降本利器,这也是此次股市震荡的原因。
谷歌这一论文即将在4月底的机器学习顶级会议ICLR 2026上发表,但团队首先要迈过这场学术争议的门槛。风波最终如何收场,仍有待观察。
嘉正网提示:文章来自网络,不代表本站观点。